On this page
A financial analyst asks your AI system: "How did TechCorp's revenue change after the CEO transition in Q3?"
Your system finds the five most semantically similar text chunks. It feeds them to a language model. The model produces a confident, well-written answer. And the answer is wrong.
Not because the language model is bad. Not because the embedding model missed something. The answer is wrong because finding similar text and reasoning over structured knowledge are two fundamentally different things. The industry built an incredible search engine and called it intelligence.
This is the reasoning gap. And it's why most enterprise AI pilots fail to deliver ROI.
Where RAG Started
In 2020, a team at Meta AI published a paper that changed how we build AI applications. The idea was elegant: instead of asking a language model to answer from memory, give it relevant documents first. Retrieve, then generate. RAG.
The insight was genuine. Language models hallucinate less when grounded in real data. Within a few years, RAG became the default architecture for enterprise AI. Vector databases, embedding pipelines, and chunking strategies became the building blocks of every AI startup's pitch deck.
And for simple queries, it works well. Ask about a single topic in a single document, and semantic similarity will find what you need. The language model fills in the rest.
The problem is that enterprise questions are rarely simple.
What RAG Is Good At (And Where It Stops)
The RAG industry has been remarkably productive. Better embeddings capture more nuance. Contextual chunking preserves document structure. Reranking models push the most relevant results to the top. Hybrid search combines keyword matching with semantic similarity. Each improvement makes retrieval incrementally better.
But here's the uncomfortable truth: all of this innovation optimizes a single operation. Semantic similarity search. Finding text that looks like the question.
Consider what happens when someone asks: "What was our quarterly revenue trend before and after the leadership change?"
This question requires five things:
- Identify the entities (the company, the leadership figures, revenue)
- Understand the temporal constraint (before and after, quarterly)
- Locate the relevant facts across multiple documents
- Connect the leadership change event to the revenue data
- Retrieve the specific numbers from the right time periods
Standard RAG addresses only step five, and imprecisely, through semantic matching rather than structured retrieval. Steps one through four are delegated entirely to the language model as an implicit, unstructured task. The model receives a pile of text chunks and is expected to figure out the rest on its own.
This works some of the time. It fails in exactly the situations where enterprises need it most: multi-document reasoning, temporal queries, numerical comparisons, and anything requiring an understanding of how facts relate to each other.
Google Research recently demonstrated that insufficient retrieved context increases error rates by 6.5x compared to having no context at all. RAG with bad retrieval is worse than no RAG.
We're Not Building a Better Search Engine
Most companies in this space are competing to build the best retrieval layer. Better vectors, faster search, smarter reranking. That's a valuable race, but it's not the one we're running.
Vrin is a reasoning engine. The distinction matters.
A search engine finds relevant text. A reasoning engine understands the structure of a question, knows how facts relate to each other across documents and time periods, identifies what it does and doesn't know, and constructs a grounded answer from structured evidence.
We started from a different question: What if we engineered each cognitive step (the perception, structuring, storage, organization, and retrieval of knowledge) based on how the brain actually solves these problems, rather than hoping the language model handles it?
It turns out we weren't the only ones thinking this way. In 2024, a team at Ohio State published HippoRAG at NeurIPS, a RAG framework explicitly built on hippocampal memory theory. Their graph-plus-vector hybrid outperformed standard RAG by up to 20% on multi-hop questions. In 2025, HippoRAG 2 extended this with dual-node knowledge graphs and Personalized PageRank, establishing the state of the art on multi-hop QA. Vrin independently arrived at the same architecture, extends it with confidence scoring, temporal reasoning, iterative reasoning, and enterprise data sovereignty, and now significantly surpasses HippoRAG 2 on MuSiQue multi-hop QA (0.469 vs 0.372 Exact Match, +26%).
The convergence isn't a coincidence. It's what happens when you take cognitive science seriously.
Why This Architecture Works
The RAG industry reinvented knowledge retrieval from scratch, and mostly ignored fifty years of cognitive science research on how brains actually organize and retrieve information.
That's starting to change. The brain uses a dual-store architecture: the hippocampus acts as a fast episodic index (recent research reveals it uses unique neural "barcodes" to tag each memory), while the neocortex builds slow, structured representations over time. This isn't a metaphor, it's been computationally validated as Complementary Learning Systems theory and directly applied to RAG by HippoRAG. The parallels to Vrin's vector store (fast episodic retrieval) and knowledge graph (slow structured knowledge) are exact.
The brain's knowledge representation turns out to be a graph. Semantic network theory has described entity-relationship structures in human memory since the 1970s. What's new is the physical evidence: a 2025 study in Science mapped the synaptic architecture of memory engrams and found that memories organize through hub-like multi-synaptic structures, not point-to-point connections. The brain builds a knowledge graph at the cellular level, with high-connectivity hub neurons playing the role that high-degree entity nodes play in Vrin's Neptune graph.
The brain also knows when to stop. The anterior cingulate cortex monitors retrieval confidence and can halt the process when information is insufficient, a metacognitive circuit that prevents confabulation. Vrin's adaptive bail-out system solves the same problem: score retrieval quality, and if it's inadequate, say "I don't know" in under 500 milliseconds instead of generating a plausible-sounding wrong answer.
Vrin didn't copy the brain. But the engineering problems are the same (organize knowledge for fast retrieval, maintain structured relationships, consolidate new information into existing schemas, and know when you don't have enough evidence to answer. When different systems solve the same problem independently, the solutions tend to converge. Recent work confirms this pattern: brain-inspired modular architectures outperform monolithic LLMs on planning tasks, and compositional memory replay) the brain's method of consolidating episodes into reusable knowledge, maps directly to how Vrin's fact extraction pipeline transforms documents into structured graph knowledge.
What's Under the Hood
When a document enters Vrin, we don't just chunk and embed it. We extract structured knowledge.
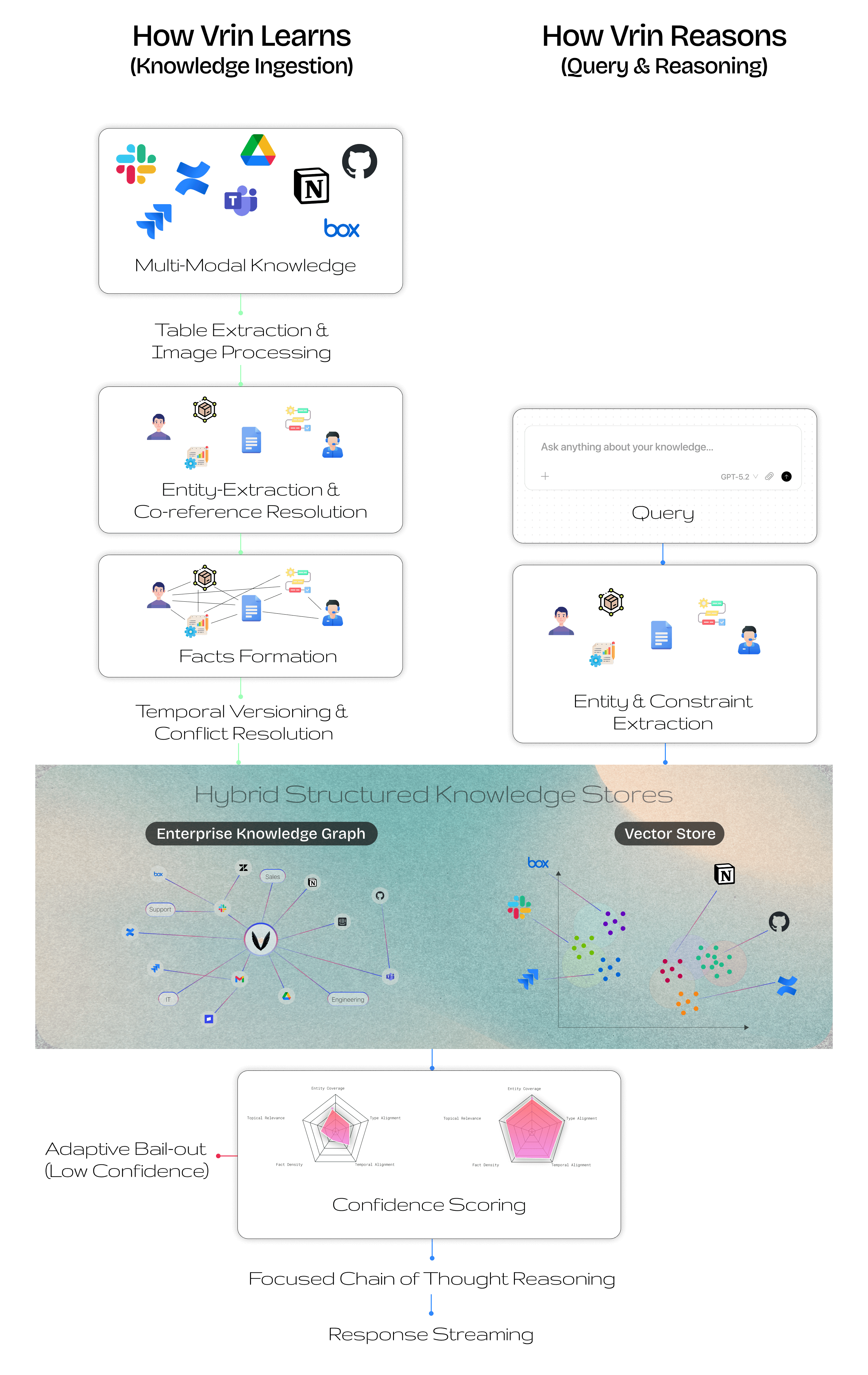
Entity-centric fact extraction identifies the real entities in a document (companies, people, products) and extracts relationships as subject-predicate-object triples. "TechCorp announced revenue of $245M" becomes a structured fact: (TechCorp, reported_revenue, $245M). Pronouns and indirect references are resolved to their concrete entities before any fact is created. This mirrors how the brain organizes memory around entities in semantic networks, a structure now confirmed at the synaptic level.
Temporal versioning tracks when facts are valid. A company's CEO changes. Revenue figures update quarterly. Standard RAG treats all information as equally current, which leads to contradictions. Vrin maintains a bi-temporal timeline: when each fact became true, when it was superseded, and what replaced it (but also when we learned it, enabling the system to distinguish event time from ingestion time. Critical for audit trails and late-arriving corrections. You can query knowledge at any point in time. This parallels Tulving's fundamental distinction between episodic and semantic memory) the brain's own system for separating time-bound events from enduring knowledge.
Constraint-aware retrieval understands the structure of your question before searching. When you ask about revenue "after Q3 2024," the system doesn't just find semantically similar text. It identifies the temporal constraint, the entity constraint, and the comparison being requested, then uses these to filter retrieval at the graph level. This approach is inspired by recent work on decomposed retrieval, where multi-hop questions are broken into atomic sub-queries before retrieval.
Confidence-scored graph traversal follows chains of relationships across documents. Multi-hop queries (questions whose answers span multiple documents) are handled through beam search across the knowledge graph, with confidence scores decaying at each hop. Complementary Personalized PageRank retrieval constructs an in-memory graph from retrieved facts and runs PPR seeded on query entities, discovering facts that beam search alone misses (particularly through indirect, multi-step entity relationships. Beam search and PPR results are merged via reciprocal rank fusion. A cross-document synthesizer identifies entities that appear in multiple sources, detects temporal overlaps, and flags contradictions. The underlying mechanism) spreading activation through a semantic network, has been formally shown to be mathematically equivalent to transformer attention.
Adaptive confidence assessment evaluates retrieval quality before generating a response. Instead of always sending retrieved context to the language model and hoping for the best, Vrin scores retrieval quality across five dimensions and makes one of three decisions: proceed with high confidence, trigger supplementary retrieval when evidence is ambiguous, or bail out entirely. The brain solves this identically: the anterior cingulate cortex monitors retrieval confidence and halts the process when evidence is insufficient, a metacognitive circuit that prevents confabulation.

When all five dimensions score highly (entity coverage, type alignment, temporal alignment, fact density, and topical relevance) the system proceeds to generate a full answer with confidence. The large polygon represents comprehensive evidence coverage.

When the polygon collapses (low entity coverage, poor topical relevance, missing temporal alignment) the system bails out in under 500 milliseconds instead of hallucinating a plausible-sounding answer. This is a deliberate architectural choice: saying "I don't know" quickly is more valuable than saying something wrong confidently.
When scores fall in an intermediate range (not confident enough to proceed, not empty enough to bail out) Vrin triggers supplementary retrieval using an exploratory strategy, merges the new evidence, and re-scores. This three-outcome design (inspired by Corrective RAG) reduces both false positives and false negatives compared to a binary threshold.
Adaptive query routing classifies each query's complexity (simple, moderate, or complex) using structural signals in under 1 millisecond, without invoking an LLM. Inspired by Adaptive-RAG, this determines how deep the pipeline goes. A simple factual lookup skips multi-hop traversal. A complex cross-document question triggers the full pipeline including parallel strategies and PPR. This avoids both over-retrieving for easy questions and under-retrieving for hard ones.
The result is that the language model receives structured facts with confidence scores, temporal metadata, source attribution, and reasoning chains. Not a pile of text chunks. Fundamentally richer context.
The Numbers
We evaluated Vrin on MultiHop-RAG, a benchmark designed specifically for cross-document multi-hop reasoning, the hardest category of question for any RAG system. Our evaluation follows BetterBench statistical guidelines: 384 stratified samples (seed=42), 95% CI [90.5%, 99.7%].

The GPT 5.2 comparison is the one that matters. GPT received the exact evidence documents for each query directly in its context window, a best-case scenario that never exists in production. Vrin retrieved from the full corpus of 609 articles under realistic conditions. Despite this disadvantage, Vrin outperformed by 16.2 percentage points.
These results demonstrate something important: the bottleneck in enterprise AI isn't the language model. It's the architecture surrounding it. Give a frontier model perfect context and it still underperforms a system that structures knowledge before reasoning over it.
Full evaluation code is open-source on GitHub.
Beyond News Articles: MuSiQue
MultiHop-RAG tests reasoning across news articles. To confirm the architecture generalizes, we evaluated on MuSiQue, a multi-hop QA benchmark where every question is constructed through single-hop composition, making reasoning shortcuts impossible. MuSiQue uses SQuAD-style Exact Match (EM) and Token F1: did the system produce the precise correct answer?
We ingested the full corpus of 4,718 Wikipedia paragraphs (38,493 stored facts after deduplication) and evaluated on 300 questions (seed=42).
| System | Exact Match | Token F1 |
|---|---|---|
| Vrin | 0.469 | 0.565 |
| HippoRAG 2 | 0.372 | 0.486 |
| Standard RAG | — | 0.457 |
Vrin surpasses HippoRAG 2 (the current state of the art on multi-hop QA) on both Exact Match (+0.097, 26% improvement) and Token F1 (+0.079, 16% improvement). The improvement is driven by Vrin's iterative reasoning engine: each multi-hop question is decomposed into dependency-ordered sub-questions, with targeted retrieval per identified knowledge gap and structured chain-of-thought injection.
Simple queries achieve the highest scores (EM=0.531, F1=0.613), with all complexity tiers benefiting from iterative reasoning. Only 1.0% of queries triggered bail-out, down from ~10% in early development.
Across two fundamentally different benchmarks (news articles and Wikipedia compositions) the same architecture produces state-of-the-art results. The bottleneck isn't the model. It's the infrastructure surrounding it.
Ready to see these results on your own data? Try Vrin free at vrin.cloud, ingest your documents and ask the questions that current tools can't answer.
Not All Queries Are Equal
The aggregate 95.1% masks an important pattern: Vrin's advantage varies dramatically by query type. Understanding where the gap is largest reveals why structured reasoning matters.
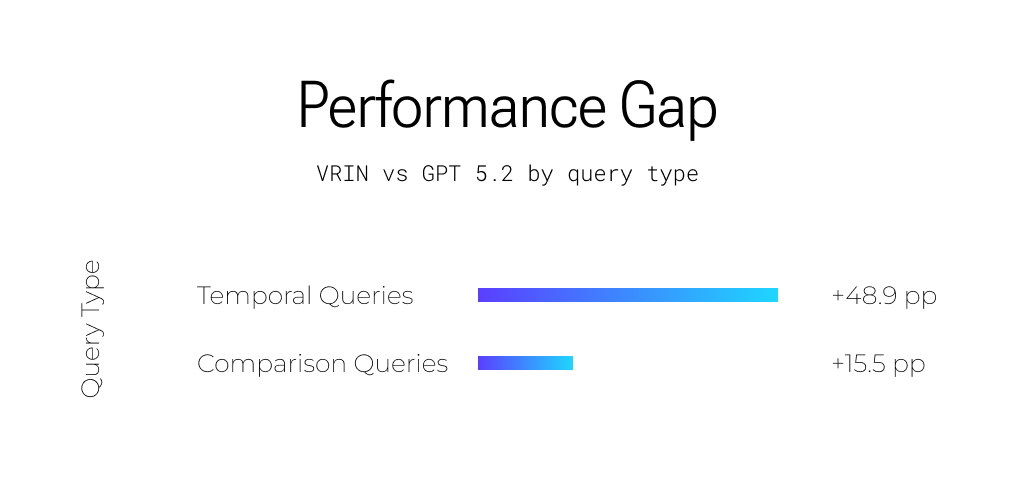
Temporal Queries (+48.9pp)
"Which company announced layoffs first. Meta or Google, and how did their stock prices compare in the following week?"
This is where the gap is widest. Temporal queries require understanding when events happened and reasoning about their sequence. Standard RAG has no concept of time, a fact from 2019 and a fact from 2024 are equally "relevant" if they're semantically similar. Vrin's temporal versioning and constraint-aware retrieval make time a first-class dimension.
Comparison Queries (+15.5pp)
"Compare the AI investment strategies of Microsoft and Google based on their Q4 earnings calls."
Comparison queries require locating equivalent facts about two or more entities across separate documents, then synthesizing them. A vector search returns chunks that mention Microsoft or Google, but not necessarily the same aspect of both. Graph traversal retrieves structured facts about both entities on the same dimensions, enabling precise comparison.
Where GPT 5.2 Excels
We believe transparency about limitations builds more trust than cherry-picked wins.
GPT 5.2 is a formidable model. On single-document inference tasks (where the answer requires logical reasoning within a provided document rather than cross-document synthesis) it performs within 0.8 percentage points of Vrin (98.4% vs 99.2%). Its advanced chain-of-thought capabilities make it genuinely impressive for tasks that fit within a single context.
GPT 5.2 also produces more fluent, natural-sounding responses. When both systems arrive at the correct answer, GPT's response is often more polished and better structured for human consumption.
Where GPT 5.2 struggles, and where Vrin's architecture creates its advantage, is when answers require:
- Temporal reasoning across time periods (revenue before vs. after an event)
- Cross-document synthesis (facts scattered across 3+ source documents)
- Entity resolution (connecting "the CEO" in one document to "Jane Rivera" in another)
- Knowing what it doesn't know (GPT generates confident answers even when context is insufficient)
These aren't edge cases. In enterprise knowledge bases, they're the majority of questions that matter. The Anthropic team has written about this challenge in their work on contextual retrieval, improving what the model receives is often more impactful than improving the model itself.
Enterprise Data Sovereignty
Enterprise data is sensitive. For many organizations, sending documents to a third-party cloud is a non-starter. Vrin supports full data sovereignty: the knowledge graph, vector index, document storage, and embedding computation can reside entirely within the customer's AWS account. Vrin's compute layer accesses customer data through time-limited, scoped credentials. The API key prefix (vrin_ vs vrin_ent_) transparently determines which infrastructure handles a request.
Enterprise data never leaves the customer's cloud.
What Comes Next
We believe the RAG industry has explored less than 5% of the available innovation space. The dominant focus has been on the retrieval subprocess: better embeddings, smarter reranking, larger context windows. But cognitive science has studied five subprocesses of knowledge work for decades, perception, structuring, storage, organization, and retrieval. Four of those five, each with established science behind them, remain largely unapplied in AI systems.
The areas we're investing in:
Adaptive retrieval depth. Not every query needs every pipeline stage. We've taken the first step: adaptive query routing now classifies complexity in under 1 millisecond and adjusts pipeline depth accordingly, simple lookups skip multi-hop traversal, complex questions trigger the full pipeline. Future versions will go further: a general knowledge question may not need retrieval at all.
Knowledge graph pattern detection and model specialization. Over time, usage patterns reveal which subgraphs and entity clusters are most frequently retrieved. A legal team queries the same regulatory frameworks. A finance team queries the same portfolio entities. We're building infrastructure to detect these patterns and automatically create memory packs from the most heavily-accessed subgraphs. These memory packs then become the foundation for fine-tuning smaller, domain-specialized models. A model trained on a healthcare team's most-queried knowledge subgraph will outperform a general-purpose model on that team's queries while running at a fraction of the cost. Structured knowledge in the graph enables precise pattern detection, pattern detection enables targeted memory pack creation, and memory packs enable efficient domain specialization, per team, per concept.
MCP integration. Vrin operates as a Model Context Protocol server. Any MCP-compatible assistant (Claude, ChatGPT, custom agents) can query Vrin's knowledge graph as a reasoning backend. Your team's structured knowledge becomes accessible from whatever AI tool they prefer.
The fundamental thesis is that AI systems will eventually be specialized like human employees, through engineering the cognitive infrastructure surrounding the model and fine-tuning specialized models from the structured knowledge it produces. Better perception, better structure, better organization, better reasoning.
We're building that infrastructure.
Read the full technical details in our whitepaper, explore the evaluation code on GitHub, or try Vrin at vrin.cloud.
Further Reading:
- Gutierrez et al., "HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models", NeurIPS 2024
- Gutierrez et al., "From RAG to Memory: Non-Parametric Continual Learning for Large Language Models" (HippoRAG 2), 2025
- Trivedi et al., "MuSiQue: Multihop Questions via Single-hop Question Composition", TACL 2022
- Jeong et al., "Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity", NAACL 2024
- Yan et al., "Corrective Retrieval Augmented Generation", 2024
- Bakermans, Behrens et al., "Constructing future behavior in the hippocampal formation through composition and replay", Nature Neuroscience 2025
- Webb et al., "A brain-inspired agentic architecture to improve planning with LLMs", Nature Communications 2025
- Fleming, "Metacognition and Confidence: A Review and Synthesis", Annual Review of Psychology 2024
- Tang et al., "MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries", 2024
- Zhu et al., "DeepRAG: Thinking to Retrieval Step by Step", 2025
- Anthropic, "Contextual Retrieval", 2024
- Perlitz et al., "BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices", 2024

Founder & CEO
Building knowledge reasoning infrastructure for enterprise AI at VRIN. We believe in transparent research and open benchmarks.